|
About. I am a Research Scientist at Google Research in Mountain View conducting foundational research on Machine Learning (ML) and Artificial Intelligence (AI). Previously, I was a Postdoctoral Researcher at the Dalle Molle Institute for Artificial Intelligence (IDSIA), after receiving my PhD in Informatics (Artificial Intelligence) in November 2020 under the guidance of Prof. Jürgen Schmidhuber. I received an MSc in Artificial Intelligence, an MSc in Operations Research, and a BSc in Knowledge Engineering from Maastricht University. I have also spent time at Google Brain, NNAISENSE, and AtonRâ as a research intern. Topics. My current research focuses on:
|

|
|
|
Selected papers are highlighted. |

|
A central component of rational behavior is logical inference: the process of determining which conclusions follow from a set of premises. Focusing on the case of syllogisms we show that, within the PaLM2 family of transformer language models, larger models are more logical than smaller ones, and also more logical than humans. At the same time, even the largest models make systematic errors, some of which mirror human reasoning biases: they show sensitivity to the (irrelevant) ordering of the variables in the syllogism, and draw confident but incorrect inferences from particular syllogisms (syllogistic fallacies). Overall, we find that language models often mimic the human biases included in their training data, but are able to overcome them in some cases. *Joint senior authors |
|
We test the hypothesis, motivated by theoretical and empirical work, that deeper transformers generalize more compositionally. We construct three classes of models which trade off depth for width such that the total number of parameters is kept constant (41M, 134M and 374M parameters). We pretrain all models as LMs and fine-tune them on tasks that test for compositional generalization. We report three main conclusions: (1) after fine-tuning, deeper models generalize more compositionally than shallower models do, but the benefit of additional layers diminishes rapidly; (2) within each family, deeper models show better language modeling performance, but returns are similarly diminishing; (3) the benefits of depth for compositional generalization cannot be attributed solely to better performance on language modeling. |

|
We leverage recent progress in diffusion models to equip 3D scene representation learning models with the ability to render high-fidelity novel views, while retaining benefits such as object-level scene editing to a large degree. In particular, we propose DORSal, which adapts a video diffusion architecture for 3D scene generation conditioned on object-centric slot-based representations of scenes. On both complex synthetic multi-object scenes and on the real-world large-scale Street View dataset, we show that DORSal enables scalable neural rendering of 3D scenes with object-level editing and improves upon existing approaches. *Equal contribution |

|
In this work, we aim to capture both the 3D structure and dynamics of real-world scenes from monocular real-world videos. Our Dynamic Scene Transformer (DyST) model leverages recent work in neural scene representation to learn a latent decomposition of monocular real-world videos into scene content, per-view scene dynamics, and camera pose. This separation is achieved through a novel co-training scheme on monocular videos and our new synthetic dataset DySO. DyST learns tangible latent representations for dynamic scenes that enable view generation with separate control over the camera and the content of the scene. |

|
Slot Attention is a popular method aimed at object-centric learning, and its popularity has resulted in dozens of variants and extensions. To help understand the core assumptions that lead to successful object-centric learning, we take a step back and identify the minimal set of changes to a standard Transformer architecture to obtain the same performance as the specialized Slot Attention models. We systematically evaluate the performance and scaling behaviour of several ``intermediate'' architectures on seven image and video datasets from prior work. Our analysis reveals that by simply inverting the attention mechanism of Transformers, we obtain performance competitive with state-of-the-art Slot Attention in several domains. |
|
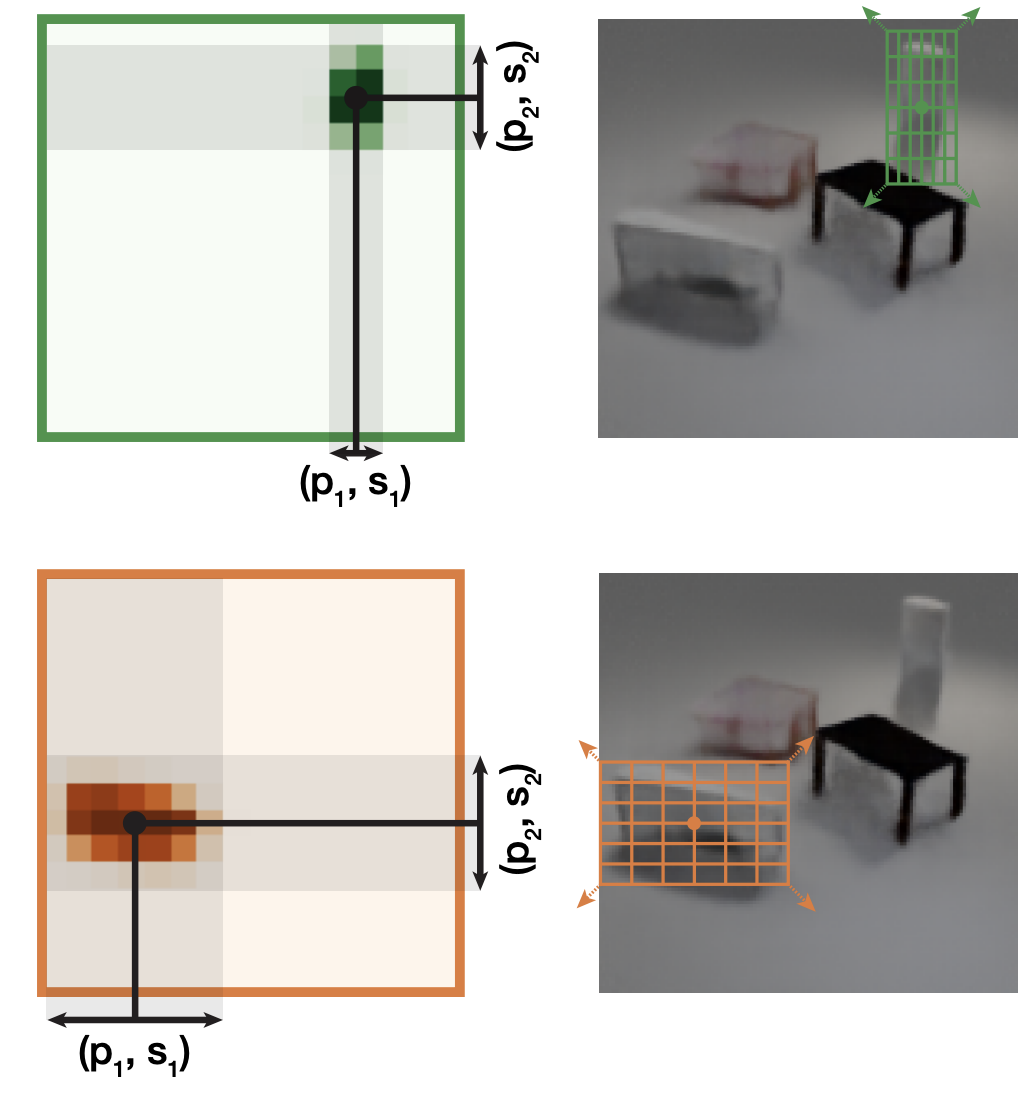
We present a simple yet highly effective method for incorporating spatial symmetries via slot-centric reference frames. We incorporate equivariance to per-object pose transformations into the attention and generation mechanism of Slot Attention by translating, scaling, and rotating position encodings. These changes result in little computational overhead, are easy to implement, and can result in large gains in terms of data efficiency and overall improvements to object discovery. We evaluate our method on a wide range of synthetic object discovery benchmarks namely CLEVR, Tetrominoes, CLEVRTex, Objects Room and MultiShapeNet, and show promising improvements on the challenging real-world Waymo Open dataset. *Equal advising |
|
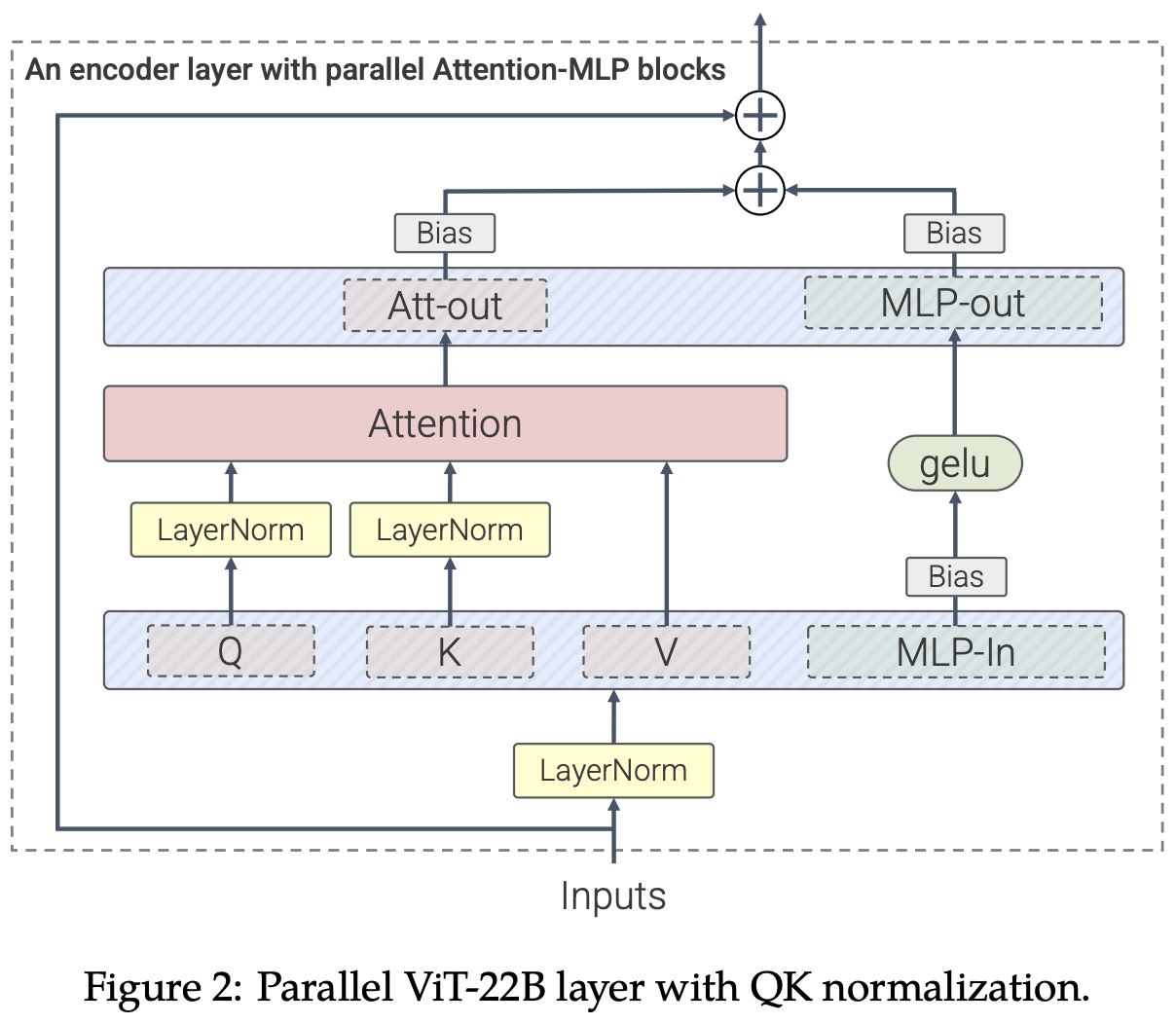
We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks, ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there. *Core contributors |
|
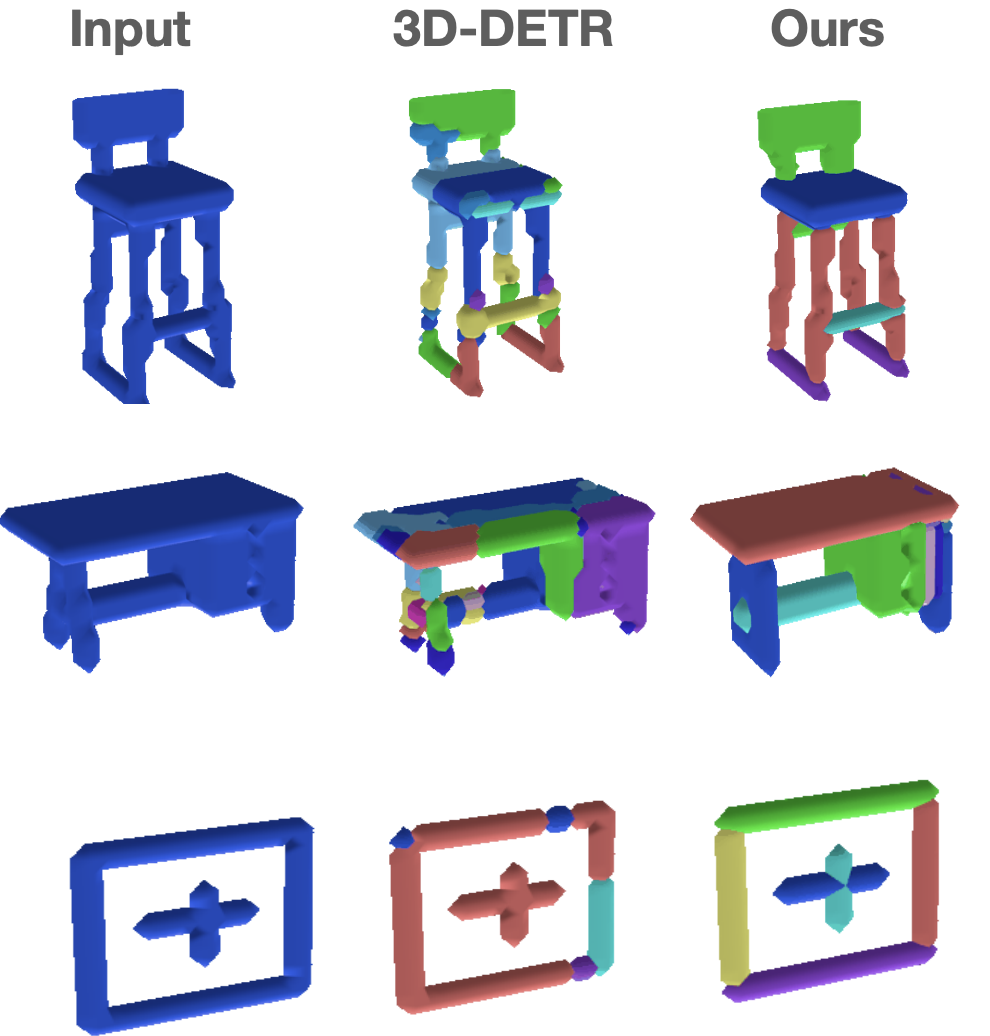
We propose Slot-TTA, a semi-supervised instance segmentation model equipped with a slot-centric inductive bias, that is adapted per scene at test time through gradient descent on reconstruction or novel view synthesis objectives. We show that test-time adaptation in Slot-TTA greatly improves instance segmentation in out-of-distribution scenes. We evaluate Slot-TTA in several 3D and 2D scene instance segmentation benchmarks and show substantial out-of-distribution performance improvements against state-of-the-art supervised feed-forward detectors and self-supervised test-time adaptation methods. |
|
The discovery of reusable subroutines simplifies decision making and planning in complex reinforcement learning problems. In this work, we propose slot-based transformer for temporal abstraction (SloTTAr), a fully parallel approach that integrates sequence processing transformers with a slot attention module to discover subroutines in an unsupervised fashion while leveraging adaptive computation for learning about the number of such subroutines solely based on their empirical distribution. We demonstrate how SloTTAr is capable of outperforming strong baselines in terms of boundary point discovery, even for sequences containing variable amounts of subroutines, while being up to seven times faster to train on existing benchmarks. |

|
We introduce SAVi++, an object-centric video model which is trained to predict depth signals from a slot-based video representation. By further leveraging best practices for model scaling, we are able to train SAVi++ to segment complex dynamic scenes recorded with moving cameras, containing both static and moving objects of diverse appearance on naturalistic backgrounds, without the need for segmentation supervision. Finally, we demonstrate that by using sparse depth signals obtained from LiDAR, SAVi++ is able to learn emergent object segmentation and tracking from videos in the real-world Waymo Open dataset. *Equal technical contribution |

|
We make progress on the problem of learning 3D-consistent decompositions of complex scenes into individual objects in an unsupervised fashion. We introduce Object Scene Representation Transformer (OSRT), a 3D-centric model in which individual object representations naturally emerge through novel view synthesis. OSRT scales to significantly more complex scenes with larger diversity of objects and backgrounds than existing methods. At the same time, it is multiple orders of magnitude faster at compositional rendering thanks to its light field parametrization and the novel Slot Mixer decoder. *Equal technical contribution |
|
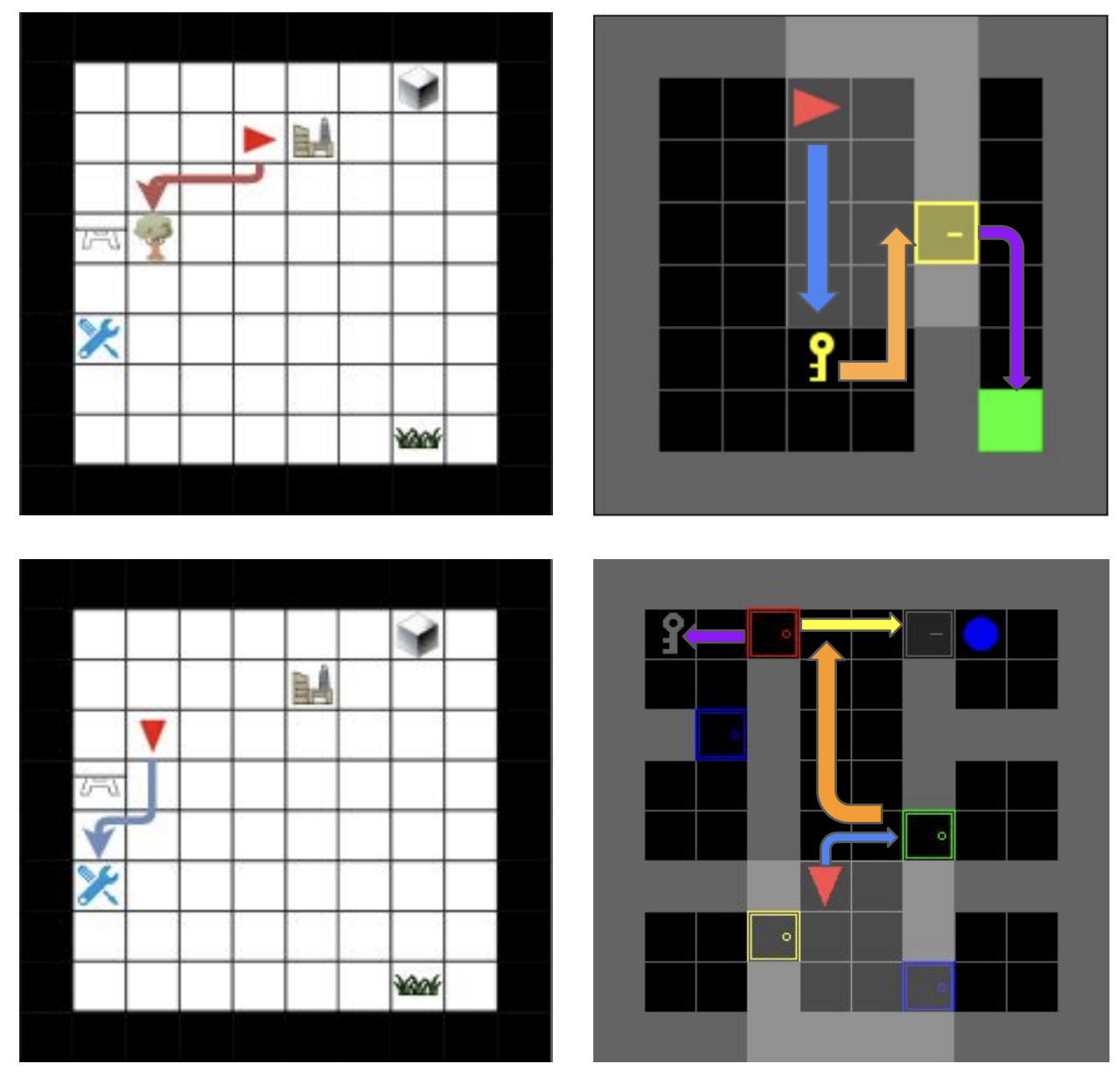
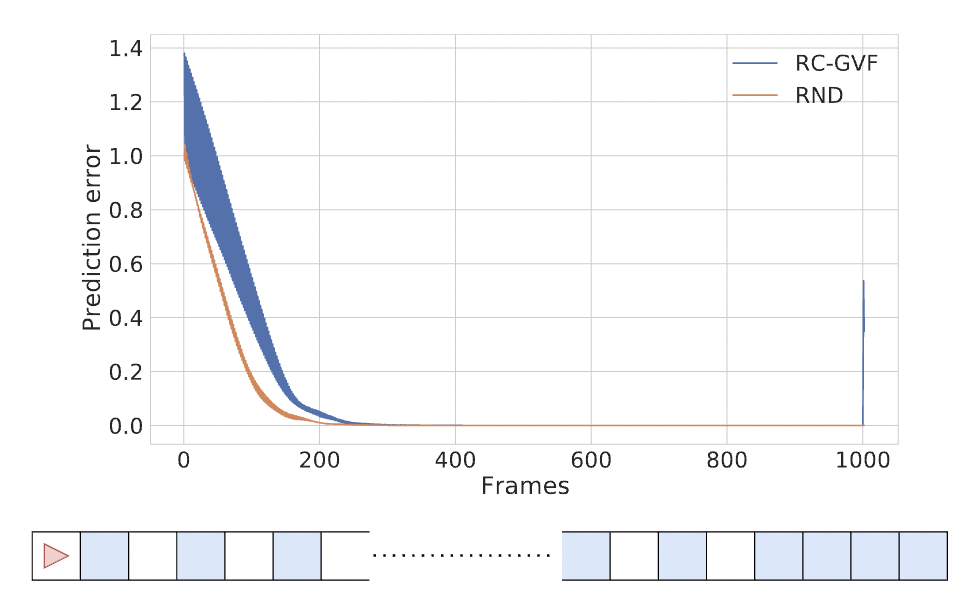
We propose random curiosity with general value functions (RC-GVF), a novel intrinsic reward function for exploration. RC-GVF derives intrinsic rewards through the task of predicting temporally extended general value functions. We demonstrate that this improves exploration in a hard-exploration diabolical lock problem. Further, RC- GVF significantly outperforms previous methods in the absence of ground-truth episodic counts in the partially observable MiniGrid environments. Panoramic observations on MiniGrid further boost RC-GVF's performance such that it is competitive to baselines exploiting episodic counts. |
|
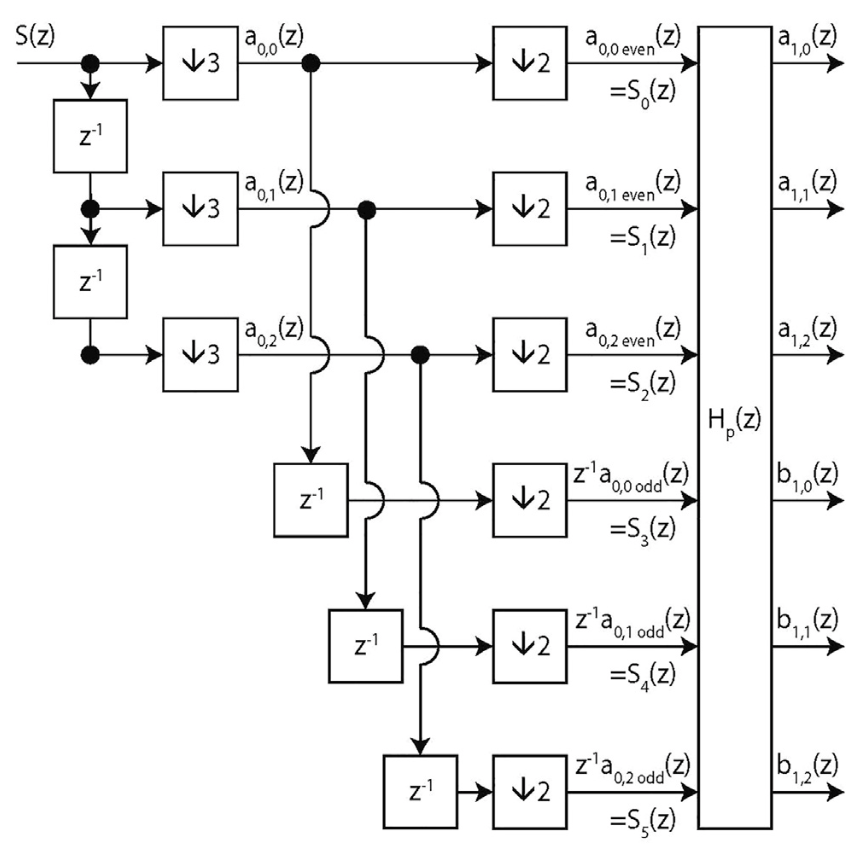
We present a full parameterization of the space of all orthogonal multiwavelets with two balanced vanishing moments (of orders 0 and 1), for arbitrary given multiplicity and degree of the polyphase filter. This allows one to search for matching multiwavelets for a given application, by optimizing a suitable design criterion. We present such a criterion, which is sparsity-based and useful for detection purposes. We also present explicit conditions to build in a third balanced vanishing moment (of order 2), which can be used as a constraint together with the earlier parameterization. This is demonstrated by constructing a balanced orthogonal multiwavelet of multiplicity three, but this approach can easily be employed for arbitrary multiplicity. |
|
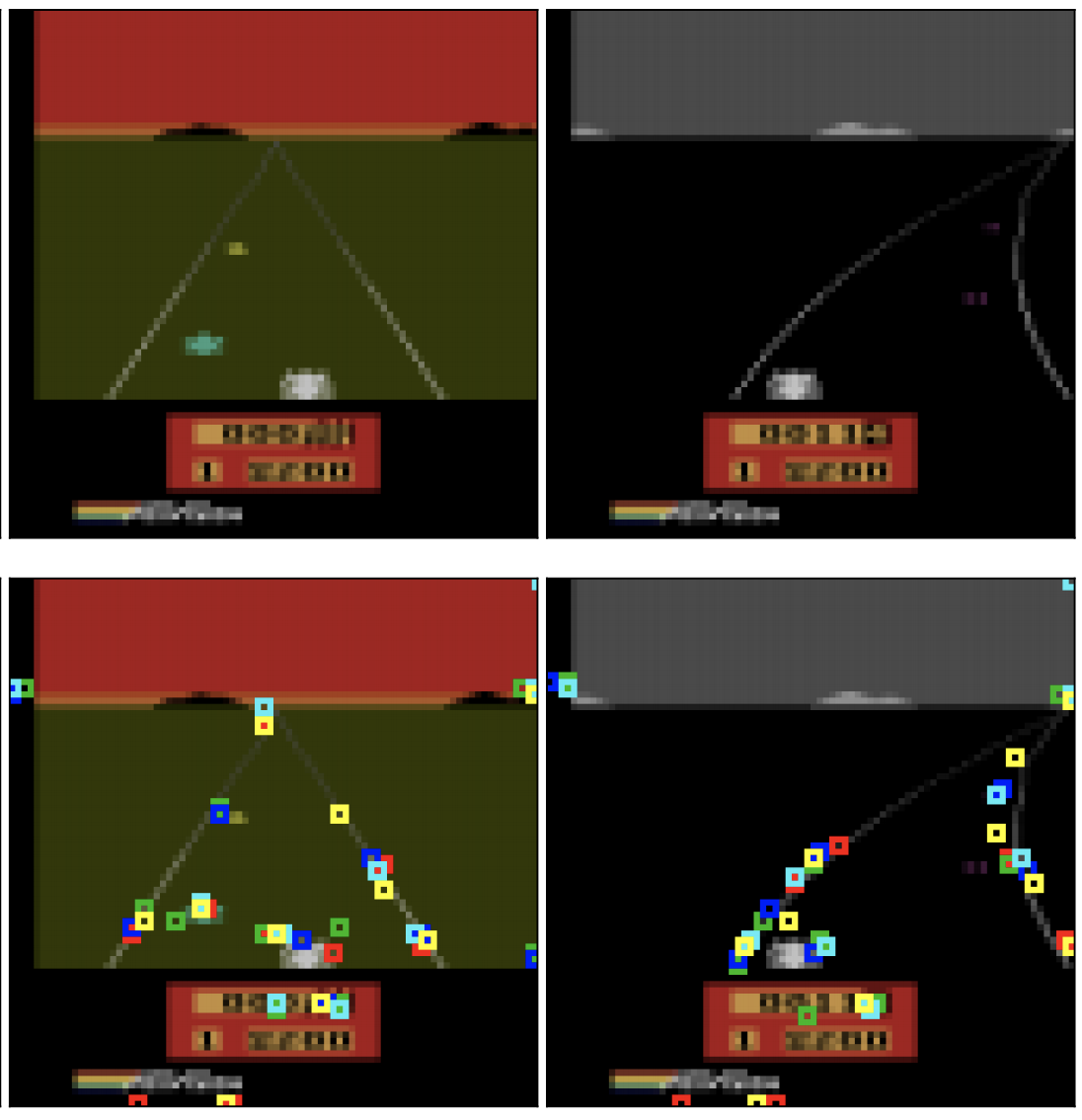
We propose PermaKey, a novel approach to representation learning based on object keypoints. It leverages the predictability of local image regions from spatial neighborhoods to identify salient regions that correspond to object parts, which are then converted to keypoints. We demonstrate the efficacy of PermaKey on Atari where it learns keypoints corresponding to the most salient object parts and is robust to certain visual distractors. Further, on downstream RL tasks in the Atari domain we demonstrate how agents equipped with our keypoints outperform those using competing alternatives. |
|
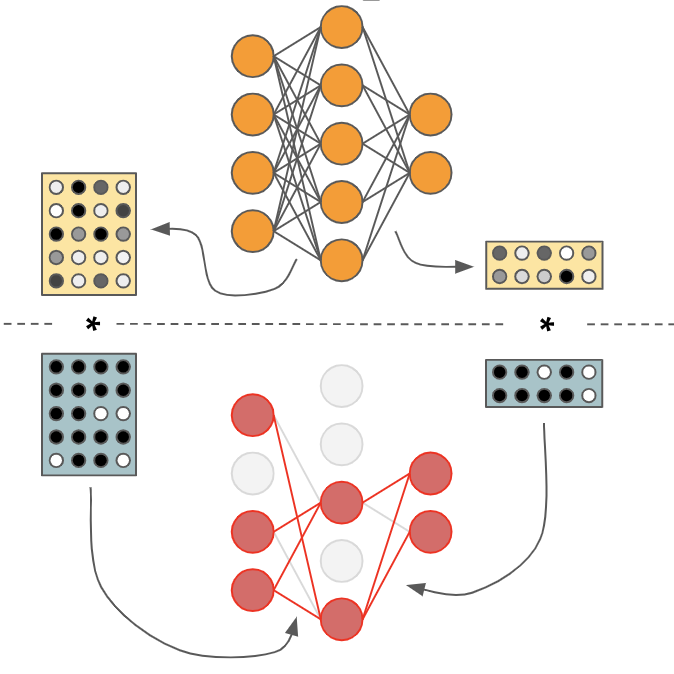
In this paper, we present a novel method based on learning binary weight masks to identify individual weights and subnets responsible for specific functions. Using this powerful tool, we contribute an extensive study of emerging modularity in NNs that covers several standard architectures and datasets. We demonstrate how common NNs fail to reuse submodules and offer new insights into the related issue of systematic generalization on language tasks. |
|
We propose a novel approach to physical reasoning that models objects as hierarchies of parts that may locally behave separately, but also act more globally as a single whole. Unlike prior approaches, our method learns in an unsupervised fashion directly from raw visual images to discover objects, parts, and their relations. It explicitly distinguishes multiple levels of abstraction and improves over a strong baseline at modeling synthetic and real-world videos. |

|
Contemporary neural networks still fall short of human-level generalization. In this paper, we argue that this is due to their inability to dynamically and flexibly bind information that is distributed throughout the network. This binding problem affects their capacity to acquire a compositional understanding of the world in terms of symbol-like entities (like objects), which is crucial for generalizing in predictable and systematic ways. To address this issue, we propose a unifying framework that revolves around forming meaningful entities from unstructured sensory inputs (segregation), maintaining this separation of information at a representational level (representation), and using these entities to construct new inferences, predictions, and behaviors (composition). Our analysis draws inspiration from a wealth of research in neuroscience and cognitive psychology, and surveys relevant mechanisms from the machine learning literature, to help identify a combination of inductive biases that allow symbolic information processing to emerge naturally in neural networks. |

|
We present a minimal modification to the generator of a GAN to incorporate object compositionality as an inductive bias and find that it reliably learns to generate images as compositions of objects. Using this general design as a backbone, we then propose two useful extensions to incorporate dependencies among objects and background. We extensively evaluate our approach on several multi-object image datasets and highlight the merits of incorporating structure for representation learning purposes. In particular, we find that our structured GANs are better at generating multi-object images that are more faithful to the reference distribution. More so, we demonstrate how, by leveraging the structure of the learned generative process, one can 'invert' the learned generative model to perform unsupervised instance segmentation. |
|
We introduce MetaGenRL, a novel meta reinforcement learning algorithm that distills the experiences of many complex agents to meta-learn a low-complexity neural objective function that affects how future individuals will learn. Unlike recent meta-RL algorithms, MetaGenRL can generalize to new environments that are entirely different from those used for meta-training. In some cases, it even outperforms human engineered RL algorithms. MetaGenRL uses off-policy second-order gradients during meta-training that greatly increase its sample efficiency. |

|
We conduct a large-scale study that investigates whether disentangled representations are more suitable for abstract reasoning tasks. Using two new tasks similar to Raven's Progressive Matrices, we evaluate the usefulness of the representations learned by 360 state-of-the-art unsupervised disentanglement models. Based on these representations, we train 3600 abstract reasoning models and observe that disentangled representations do in fact lead to better up-stream performance. In particular, they appear to enable quicker learning using fewer samples. |
|
In order to meet the diverse challenges in solving many real-world problems, an intelligent agent has to be able to dynamically construct a model of its environment. Objects facilitate the modular reuse of prior knowledge and the combinatorial construction of such models. In this work, we argue that dynamically bound features (objects) do not simply emerge in connectionist models of the world. We identify several requirements that need to be fulfilled in overcoming this limitation and highlight corresponding inductive biases. *Both authors contributed equally |

|
We propose Fréchet Video Distance (FVD), a new metric for generative models of video based on FID, and StarCraft 2 Videos (SCV), a collection of progressively harder datasets that challenge the capabilities of the current iteration of generative models for video. We conduct a large-scale human study, which confirms that FVD correlates well with qualitative human judgment of generated videos, and provide initial benchmark results on SCV. *Both authors contributed equally |
|
|
We propose to structure the generator of a GAN to consider objects and their relations explicitly, and generate images by means of composition. On several multi-object image datasets we find that the proposed generator learns to identify and disentangle information corresponding to different objects at a representational level. A human study reveals that the resulting generative model is better at generating images that are more faithful to the reference distribution. |
|
We present a novel method that learns to discover objects and model their physical interactions from raw visual images in a purely unsupervised fashion. It incorporates prior knowledge about the compositional nature of human perception to factor interactions between object-pairs and learn efficiently. On videos of bouncing balls we show the superior modelling capabilities of our method compared to other unsupervised neural approaches that do not incorporate such prior knowledge. |
|
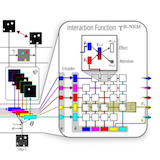
We propose a novel approach to common-sense physical reasoning that learns physical interactions between objects from raw visual images in a purely unsupervised fashion. Our method incorporates prior knowledge about the compositional nature of human perception, enabling it to discover objects, factor interactions between object-pairs to learn efficiently, and generalize to new environments without re-training. |

|
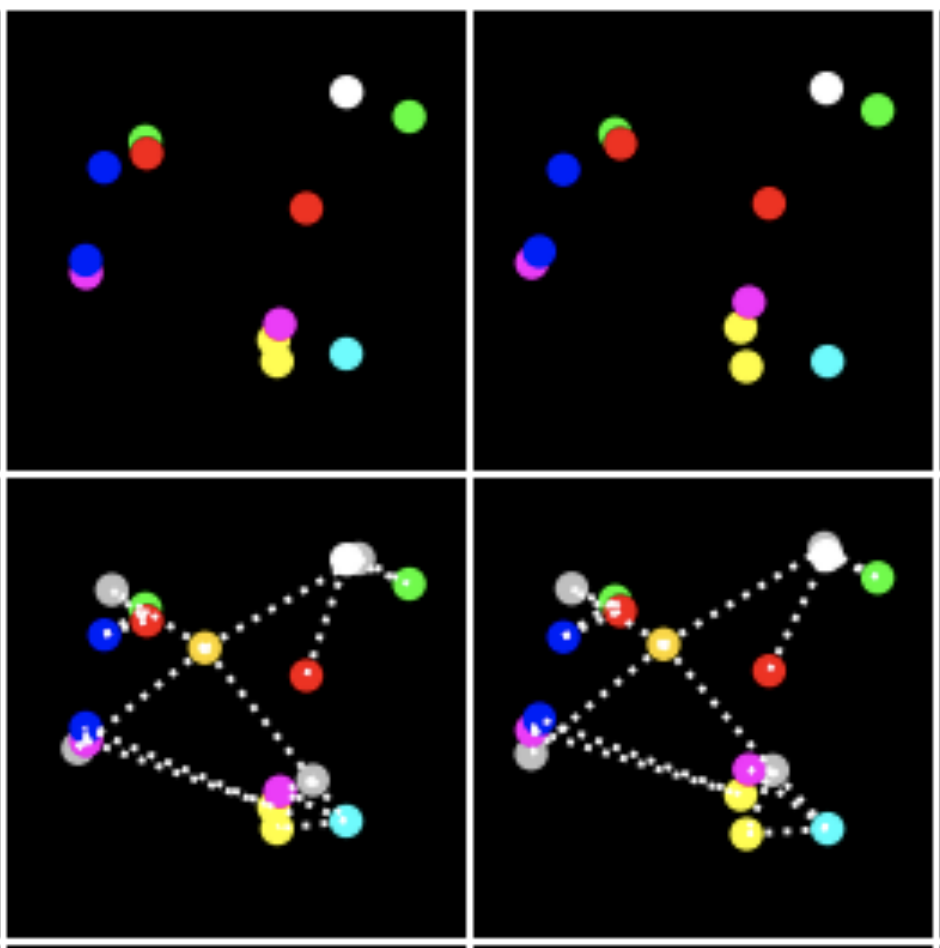
In this paper, we explicitly formalize the problem of automatically discovering distributed symbol-like representations as inference in a spatial mixture model where each component is parametrized by a neural network. Based on the Expectation Maximization framework we then derive a differentiable clustering method that simultaneously learns how to group and represent individual entities. *Both authors contributed equally |
|
A new indirect scheme for encoding neural network connection weights as sets of wavelet-domain coefficients is proposed. It exploits spatial regularities in the weight-space to reduce the gene-space dimension by considering the low-frequency wavelet coefficients only. The wavelet-based encoding builds on top of a frequency-domain encoding, but unlike when using a Fourier-type transform, it offers gene locality while preserving continuity of the genotype-phenotype mapping. |
- In February 2020 I gave a remote talk at the Stanford Neuroscience and Artificial Intelligence Laboratory (NeuroAILab) on "Representation Learning for Relational Reasoning".
- In June 2019 I gave an invited talk at the Max Planck Institute for Intelligent Systems (Tübingen) on "Incorporating Objects in Neural Networks", slides are available here.
- At ICML 2019, I gave a contributed talk at the Workshop on Generative Modeling and Model-Based Reasoning for Robotics and AI about our current perspective on Objects and Systematic Generalization in Model-based RL.
- At NIPS 2017, I gave a contributed talk at the Cognitively Informed AI Workshop about Relational Neural Expectation Maximization, slides are available here.
- In September 2017, I gave a talk at Google Brain (Zurich) on symbol-like representation learning with Neural Expectation Maximization.
|
|